Est-ce que Tim Berners-Lee (Association W3C) avait conscience lorsqu’il inventa HTTP et le web en 1989 de la portée de son invention dans la démocratisation du savoir ? Je veux parler bien sûr protocole de transfert hyper texte et de son langage référent le HTML pour Hyper Text Markup Language.
Si HTTP cela ne vous parle pas vous pouvez toujours vous référer à mon article sur le modèle OSI qui liste une partie des protocoles de communication sur l’Internet mais sachez que c’est ce que vous tapiez en premier il y’a encore peu dans toute barre d’adresse de votre navigateur Internet.
Un Passage au CERN et la révolution HTTP
Si Tim avait pour but alors qu’il s’ennuyait de révolutionner le cheminement de l’information lors de son passage au Centre Européen de recherche nucléaire (CERN) il y’a un élément fondamental qu’il n’avait peut-être pas prévu, ou du moins dont il a sûrement sous-estimé la portée dans les usages et dans nos vies : cliquer sur un lien ou un mot pour en connaître le sens…
Je veux parler de la fameuse balise A qui signifie « Anchor » ou ancre du langage HTML qui permet de transformer un bloc de mot, une image ou encore une simple lettre en un « hyperlien » pour faire référence à une autre page ou à une page de définition. Sur ce modèle a été bâti le succès de Wikipedia et toutes les encyclopédies en ligne ou autres dictionnaires numériques qui sont des véritables accélérateurs de mémorisation.
Grâce à HTTP il a rendu accessible ce qui était réservé à une élite lors de processus de discussions ou deux interlocuteurs rebondissent sur un mot ou une idée pour se l’approprier. Il a redéfini la pédagogie de l’apprentissage, universitaire et académique.
Il n’est pas étonnant que le vieux monde ou les régimes totalitaires aient été réfractaire à l’avènement du web et des technologies de l’information quand chaque étudiant ou autodidacte avait accès à des trésors de connaissances.
Si on en a la volonté tout est à notre portée pour pouvoir apprendre et s’exercer : en quelques clics, prises de notes, sites spécialisés pour peu que l’on connaisse les bases du domaine que l’on souhaite approfondir : mathématiques, biologie moléculaire et c’est un formidable vecteur d’égalité des chances.
Certes, cela ne remplacera jamais les livres et leurs approche pédagogique mais avouez que nos bons Larousse ont pris un vrai coup de vieux lorsque nous devons passer d’une page à l’autre de mots classés par ordre alphabétique pour approfondir un ensemble de définition…
HTTP et les dictionnaires numériques
Une initiative que je trouve extraordinaire et dont je souhaitais vous faire part ici est celle du CNRS avec son trésor de la langue française, un centre de ressources national de ressources textuelles et lexicales qui a été mis en ligne vers 2008 que j’ai découvert pendant mes études accessibles sur CNRTL.FR et dont chaque mot contrairement à wikipedia est un hyperlien.
Cette fonctionnalité originale du tout hyperlien avait aussi été déployé sur le dictionnaire académique d’oxford. Il favorise la pensée en arborescence, peut créer des intelligences et des mécanismes de pensée ou de mémorisation qui sur le plan cognitif peuvent s’avérer tout à fait particulières.
Sur ce dictionnaire, par un simple clic gauche un menu s’ouvre et vous avez accès à la lexicographie, la morphologie, l’étymologie, la synonymie, l’antonymie,la proxémie, la concordance complète du mot comme le montre cette image de la définition du terme « primitive ».
S’approprier la définition d’un mot c’est maîtriser son emploi dans la vie courante ou académique, chaque définition est surligné pour stimuler votre mémoire visuelle et vous pouvez paramétrer chaque couleur si votre rétine et vos cônes sont plus sensibles à certaines d’entre elles.
Les définitions sont classés par matière ce qui permet de se rendre compte de toute la richesse de notre langue car chaque mot revêt différentes acceptions. Les syntagmes en vert sont des groupes nominaux qui permettent de comprendre l’emploi du terme avec d’autres mots qui lui sont associés.
Exemple du mot « primitif » sur le dictionnaire du centre national de ressources textuelles et lexicales. J’ai choisi volontairement ce mot car il revêt plusieurs acceptions et permet de comprendre l’intérêt du dictionnaire.
C’est pour cela que je fais référence souvent à ce dictionnaire dans mes articles pour vous inciter à l’utiliser et développer votre pensée analytique. Le pouvoir de la connaissance est entre nos mains.
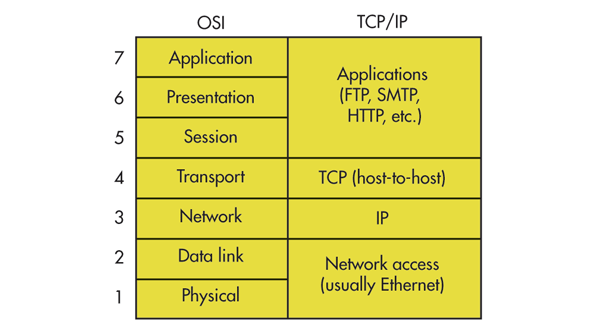
Après avoir abordé le modèle OSI et ses différentes couches, intéressons au nous au modèle TCP/IP. (Protocole de contrôle de transmission)/ (Protocole Internet).
Rappel : si vous n’avez pas cliqué sur le mot protocole pour en connaître la définition à partir du dictionnaire du CNRS (tout en bas) Laissez moi vous la donner :
Ensemble des règles qui permettent à un utilisateur de se connecter sur un réseau ou à diverses parties de ce réseau de communiquer entre elles. (Ce mot est fondamentalement synonyme de procédure).
Son emploi est cependant réservé aux cas présentant un certain degré de complexité.
TCP/IP se présente donc comme un protocole hybride, en effet TCP ne va pas sans IP l’un est sur la couche 4 Transport (TCP) l’autre est sur la couche 3 Réseau (IP). IP est ce qui permet à votre carte réseau d’avoir un adressage donc une suite de chiffres décimaux encodés sur 32 bits soit 4 octets de la forme 192.168.100.55 pour communiquer mais nous y reviendrons plus tard.
Le modèle TCP est plus ancien et plus simple que le modèle OSI, il se divise en 4 couches.
Le schéma suivant présente les correspondances entre les couches du modèle OSI et du modèle TCP :
OSI Model vs TCP Model @Electronic Design
Pour bien comprendre, les protocoles de plus haut niveau tels que HTTP se basent sur le protocole TCP pour fonctionner. Même si HTTP est principalement un protocole applicatif (Couche 7 du modèle OSI comme nous l’avons vu dans l’article précédent.) Le modèle TCP permet de mettre en valeur l’architecture selon laquelle ces protocoles se basent sur TCP pour fonctionner, c’est pourquoi les couches du modèle OSI 5,6,7 sont regroupés. De plus il est plus ancien et moins complexifié.
Il existe un autre protocole de transport moins fiable et plus léger que nous verrons plus tard : UDP.
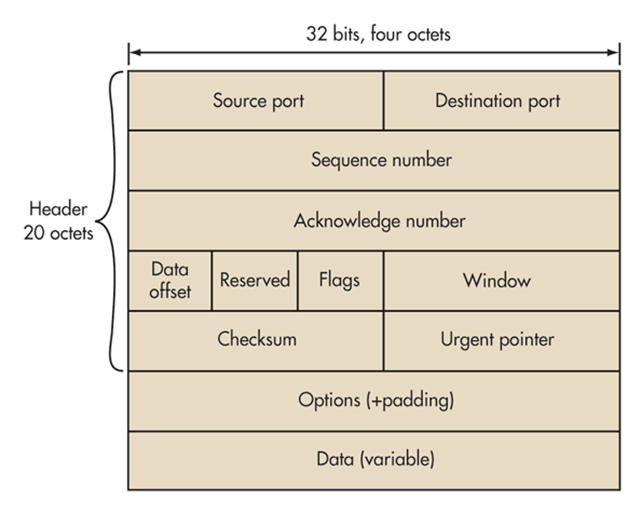
Le protocole TCP s’encapsule et se désencapsule (tout dépend si l’ordinateur est émetteur (Source) ou récepteur (Destination).
Les cinq premières couches totalisent 160 bits. Chaque couche est donc de 32 bits soit 4 octets, on trouve 5 couches.
1/ 1ère couche de 4 octets : Source Port, Destination Port. (Porte ouverte par le logiciel ou protocole qui va chercher à communiquer)
2/ Ensuite suivent des couches dont le numéro de séquence, le numéro d’acquittement, une réservation et les flags (drapeaux) qui sont des bits de contrôle ou de signalisation qui représentent 8 bits. Vient une couche optionnelle pour le rembourrage et enfin la couche finale pour les données.
Il est très important de souligner que le protocole TCP va chercher à communiquer en passant par les portes logiques (ouvertes par les logiciels de l’ordinateur).
Ces ports sont complémentaires de l’adresse IP et tous ensemble : 192.168.1.100:41340 (Adresse en gras, Port en rouge) les deux sont ce l’on appelle communément en informatique réseau un socket.
Cette image d’en-tête est la même que celle du dessus sauf qu’elle présente les différents flags ou bits de contrôle ou de signalisation : URG, ACK, PSH, RST, SYN, FIN.
Pour faire une analogie ce sont les panneaux du code de la route des communications électroniques.
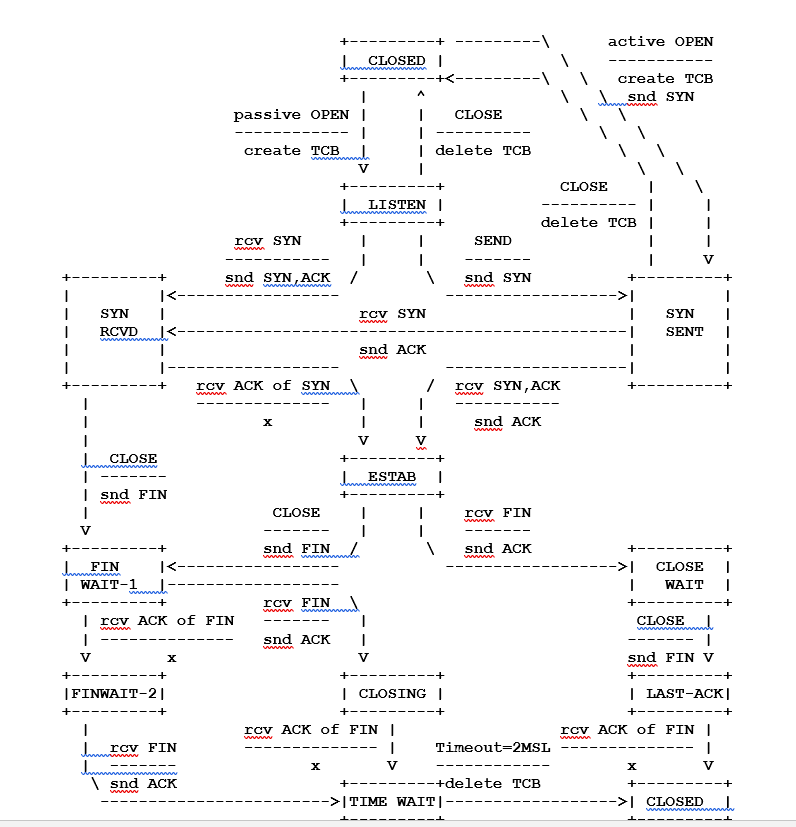
Ce schéma est assez difficile à lire mais il a le mérite d’être très fidèle à ce qui se produit quand deux ordinateurs communiquent via TCP.
SYN, ACK, FIN sont donc les flags, bits de contrôle ou signalisations qui sont les indicateurs clés du fonctionnement du protocole.
Les encadrés sont les différents états de TCP que vous pouvez retrouver en tapant encore une fois « netstat » via une invite de commande sur votre ordinateur. Pour encore faire une analogie c’est un peu l’état du moteur de votre voiture.
Il existe encore d’autres bits de contrôles ou signalisation tels que PSH pour push, RST pour ReSet, URG pour urgent ou encore CWR pour la congestion réseau étudiée via une RFC à elle seule (n°3168).
Le protocole IP(Internet Protocol)
Le protocole IP a également son propre en-tête :
Qu’est-ce qu’une adresse IP ?
Une IP par exemple 192.168.100.254 interprété ici dans sa forme décimale mesure 32 bits soit 4 octets (8 bits):
L’en-tête se lit de haut (départ) en bas (fin) en fonction si vous êtes l’émetteur ou le récepteur voir modèle OSI.
1ère ligne :
Version : 4 bits | Donne des informations sur le type d’en-tête, savoir si vous êtes V4 ou V6 par exemple. Le format présenté est celui de la V4.
Longueur de l’en tête : 4 bits | code la longueur de l’en-tête, l’unité étant un mot de 32 bits, il indique le commencement de la donnée.
Type de service : 8 bits | donne une indication sur la qualité de service demandée cependant cela reste un paramètre abstrait. Cette option est utilisée pour guider le choix de paramètres quand un datagramme transite a partir d’un réseau spécifique. Certains réseaux offrent un mécanisme de priorité. Certains types de trafic vont êtres traités préférablement plutôt qu’un autre. Le choix principal obéit à trois contraintes : un court délai, un débit d’erreur bas, ou un gros volume de sortie.
Taille totale : 16 bits | Le champ taille totale est un la longueur du message de données complet ou datagramme incluant l’en-tête et la data mesurées en octets. Ce champs peut seulement coder un datagramme de 65,535 octets. Une telle longueur serait impossible à gérer pour la majorité des réseaux. L’hôte acceptera un datagramme d’une longueur d’environ 576 octets que ce soit un datagramme ou un fragment. Il est par ailleurs recommandé de ne pas envoyer de datagramme de plus de 576 bits à moins qu’ils soient sure que la destination est capable de les accepter.
2ème ligne :
Identification : 16 bits | Une valeur d’identification, allouée par l’émetteur pour identifier les fragments d’un seul datagramme ou message.
Flags : 3 bits | Ce sont des bits de signalisations ou contrôle : le bit 0 est réservé il doit rester à 0. Le bit 1 pour (DF) (Don’t fragment) à 0 indique que la fragmentation est possible, à 1 il indique que le bit est non-fractionnable donc il sera détruit. Le bit 2 pour (MF) More fragments : si il est à 0 c’est le dernier fragment, si il est à 1 on a un fragment intermédiaire.
Fragment offset : 13 bits | Ce champ indique l’écart du premier bit de fragment en lien avec tout le message.Offset en anglais se traduit par la distance avec un élément placé. Cette position relative est mesuré en 64 bits soit 8 octets. L’écart du premier fragment est égal à 0.
3ème ligne :
Time to live(Temps de vie) : TTL : 8 bits | Ce champ limite le temps qu’un datagramme reste dans le réseau, si ce champ est égal à zéro, le message doit être détruit. Ce champ est modifié durant le traitement de l’en tête Internet. Chaque module Internet (routeur) doit retourner au moins une unité une fois de ce champ durant la transmission d’un paquet même si la prise en charge de ce message par le module dure moins d’une second. Ce temps de vie doit être vue comme la durée de temps maximum pour qu’un datagramme existe . Ce mécanisme existe par nécessité de détruire n’importe quel message qui n’a pas été correctement transmis au réseau.
Lorsque vous faites un ping -i 32 www.google.com sur une requête commande dans Windows, vous envoyez des paquets qui peuvent traverser jusqu’à 32 routeurs avant d’être détruit. -i est le paramètre de la commande TTL.
Ping est un logiciel dont le nom est ce qu’on appelle un acronyme arrière ou en anglais (backronym) pour packet internet grouper. Il fait partie de la suite de logiciels du protocole générique Internet Control Management Protocol (ICMP).
Protocol :8 bits | Ce champ indique quelle version du niveau supérieur de protocole est utilisée dans la section de donnée du message Internet. Les différentes valeurs allouées pour des protocoles variés sont listés dans les nombres assignés dans la RFC 1060.
CRC(contrôle de redondance cyclique) 16 bits | Somme de redondance cyclique calculée uniquement dans l’en-tête. Certain des champs de l’en-tête sont modifiés durant leur transit a travers le réseau, cette somme de contrôle doit être recalculée et vérifié à chaque endroit du réseau ou l’en-tête est réinterprété.
Lorsque vous avez en face de vous un administrateur réseau, une de ses principales fonctions va être de paramétrer le nombre d’ordinateurs qui vont pouvoir communiquer entre eux à l’intérieur d’un réseau.
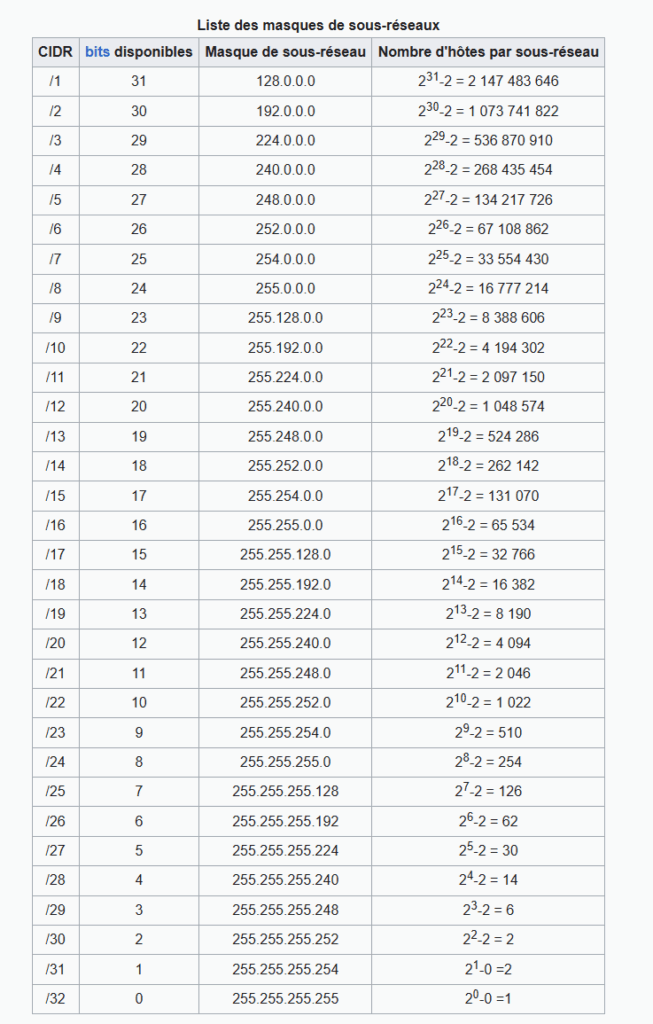
Pour se faire il va s’appuyer sur un masque de sous réseau, ainsi lorsque l’on lit la syntaxe suivante 192.168.100.0/24, cela veut dire que comme l’adresse est codée sur 32 bits que 24 bits sont masqués.
Si 24 bits sont masqués, les 8 derniers sont disponibles puisqu’une adresse est codée sur 32 bits…
Ainsi j’obtiens donc une adresse réseau(net id) en 192.168.100.XXX
XXX étant la partie disponible soit 8 bits soit 2^8 hôtes disponibles soit 256. A cela il faut que j’enlève -2 pour la réservation. Dans ce plan d’adressage, je ne pourrai avoir que 254 machines qui communiquent entre elles.
Mon sous réseau correspond a 192.168.100(net id). X et me donne un nombre d’hôtes disponibles(host id) de 254 qui pourront avoir une adresse dans ce plan d’adressage. En effet je peux avoir une machine en 192.168.100.2 ou en 192.168.100.3, 192.168.100.4 192.168.100.5, jusqu’à 255 etc… .
Ces deux machines étant sur le réseau 192.168.100(net id) elles pourront communiquer entre elles.
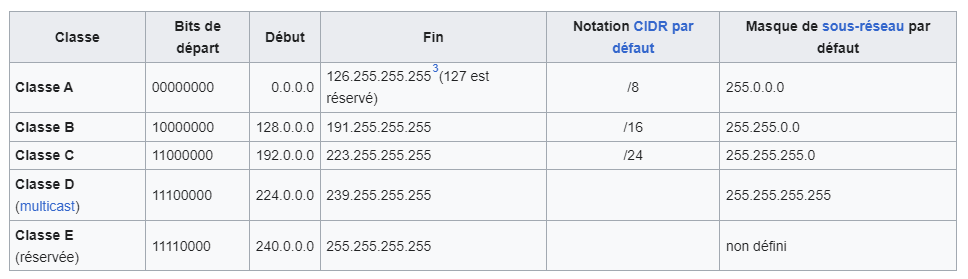
Si la notation CIDR s’est répandue, c’est pour redéfinir le système un peu archaïque des systèmes de classes d’adresses.
En effet, à l’origine les adresses IP étaient divisées en cinq classes :
Une adresse IP de classe A dispose d’une partie net id comportant uniquement un seul octet.
Une adresse IP de classe B dispose d’une partie net id comportant deux octets.
Une adresse IP de classe C dispose d’une partie net id comportant trois octets.
Les adresses IP de classes D et E correspondent à des adresses IP particulières.